[AWS Cloud Fundamental Notes] Kinesis、EMR and Redshift
Introduction to Kinesis, EMR and Redshift usage and operational mechanism
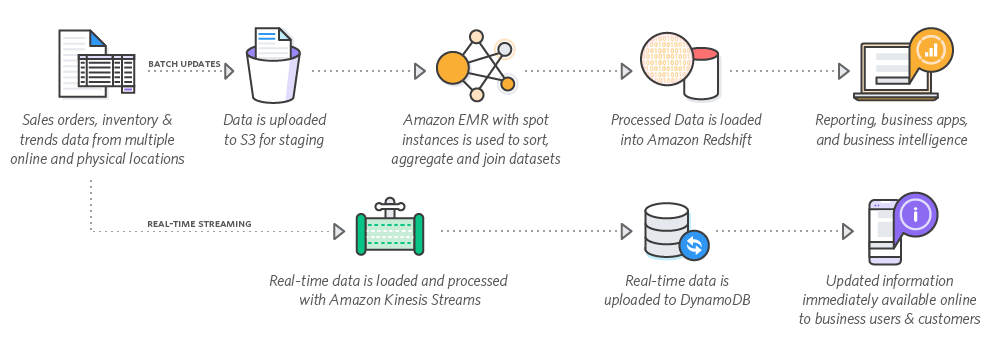
Used for big data architecture
graph LR; data-reception-->data-processing-->data-warehousing;
Corresponding Services
Amazon Kinesis
Kinesis : Specialized in collecting and streaming big data, supporting two major data types:
- Video: Using Kinesis Video Streams
- General data: Using Kinesis Data Streams
The party responsible for uploading data to Kinesis, such as various sensors, is called a Kinesis Producer.
The output data is called a Data Record and is stored in the Kinesis Stream.
Shard
There are multiple “shards” in a stream, responsible for buffering data dispersal.
When data traffic increases, the number of shards needs to be increased to ensure sufficient processing speed.
Each shard can write up to 1000 records per second, with a total of up to 1MB, and read up to 2MB per second.
Kinesis Consumer
The system that extracts and operates on data is called a Kinesis Consumer.
Amazon Elastic MapReduce(EMR)
The underlying engine of AWS EMR
is the open-source big data processing system Hadoop.
It is the most common Kinesis Consumer and is the AWS cloud version of Hadoop.
The service is based on EC2 Instances and can be accessed via SSH to the operating system inside EMR for operation.
The organized data is sent to S3 or Redshift.
Redshift
Redshift : A big data data warehousing solution for data analysis, is a column-based clustered database.
Main uses:
- Data Warehousing: Stores dense storage machines
- Data Analysis: Computes intensive machines




