[大話 AWS 雲端架構筆記] Kinesis、EMR 與 Redshift
簡介 Kinesis、EMR 與 Redshift 的使用方法和運作機制
用於大數據架構
graph LR; 資料接收-->資料處理-->資料倉儲;
對應服務
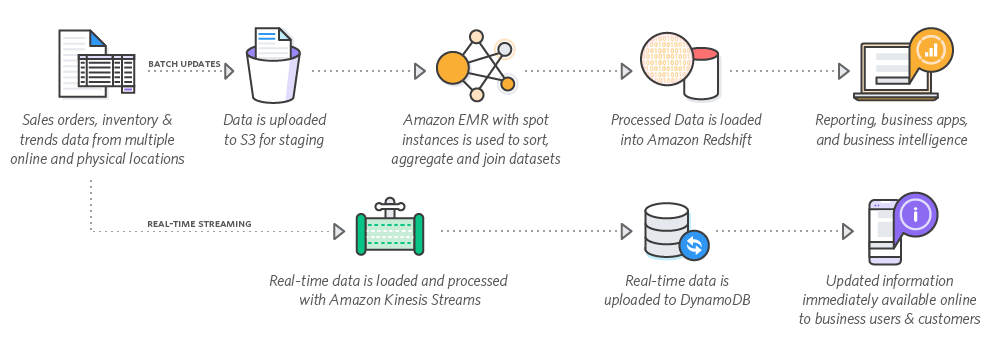
Amazon Kinesis
Kinesis :專門做大數據的搜集與串流,支援兩大數據類型
- 影片:使用 Kinesis Video Stream
- 一般資料:使用 Kinesis Data Stream
負責上傳資料到 Kinesis 的一方,例如各種感測器被稱為Kinesis Producer
產出來的數據稱作Data Record,會存放到 Kinesis Stream 裡面
Shard
在 Stream 中有多個「分片(Shard)」,負責做數據的分散緩衝
當數據流量提升時,需要增加 Shard 數量確保足夠的處理速度
每個 Shard 每秒最多寫入 1000 筆數據,總和不超過 1MB
每秒最多讀取總和不超過 2MB
Kinesis Consumer
提取數據操作的系統被稱作Kinesis Consumer
Amazon Elastic MapReduce(EMR)
AWS EMR
的底層引擎是開源大數據處理系統 Hadoop
是最常見的 Kinesis Consumer,是 Hadoop 的 AWS 雲端版本
服務的底層是 EC2 Instance
能透過 SSH 連進 EMR 內的作業系統進行操作
整理後的資料會送到S3 或是 Redshift
Redshift
Redshift :資料分析用的大數據資料倉儲,是一個 column-base 的叢集化資料庫
主要用途:
- 資料倉儲:儲存密集型(Dense Storage)的機器
- 資料分析:運算密集型(Dense Compute)的機器




